# 前言
> 写这篇文章的目的其实跟[聊一聊索引的数据结构](https://www.zhezhi.press/archives/indexanddatastructure)是一样的,是为了总结一下学过的知识;
在某次面试中,面试官问我关于索引的数据结构以后抛出的**说说复合索引**这个问题,感觉自己答得不算好,笔者之前对索引的数据结构这块了解的还算比较清晰,所以回答的也比较好,但被问到复合索引的时候感觉自己只能比较模糊的说个大概(把不同字段组合在一起作为索引,可以提高性能等),复盘以后认为确实包括认知和表达都不到位,下面开始进入正题吧!
# 联合索引
```sql
ALTER TABLE `table_name` ADD INDEX (`a`,`b`);
```
## 作用
- 假如有一条SQL语句需要用到多个条件,例如
```sql
SELECT * FROM user_info WHERE user_city=40 AND user_age=18;
```
那么当引擎在检索`user_age`字段时(由于已经检索过满足`user_city=40`的行了)使得数据量大大缩小,增大了索引的命中率和效率。
- 联合索引的体积比单独索引的体积小,减小开销(可以理解为(a,b,c)一个索引树可以提供(a)(a,b)(a,b,c) 三个索引 写入复杂度和磁盘占用开销大大减小)
- 更方便利用覆盖索引
## 联合索引命中的本质-->从索引树的结构出发谈到最左前缀匹配原则
> 虽然自己知道最左前缀匹配原则 但是在面试的时候完全没有答出来;在这里我认为提到了联合索引一定绕不开最左前缀匹配原则的 这里比较重要!然后我在这里默认读者已经掌握了**最左前缀匹配原则**的基本内容,所以不会在这里赘述如何利用最左前缀匹配原则从理论上分析一条SQL语句是否走了索引
比如前面我们已经提到了,当我们创建了一条`(a,b,c)`的联合索引后,相当于我们拥有了`(a)`单列索引,`(a,b)`、`(a,b,c)`联合索引,因此想要索引生效只能使用`a`、`a,b`、`a,b,c`三种组合。
*注:`a,c`也可以走索引,但实际上只走了`a`*
然后我们来看假设对`(a,b)`字段建立索引,索引树如下图所示
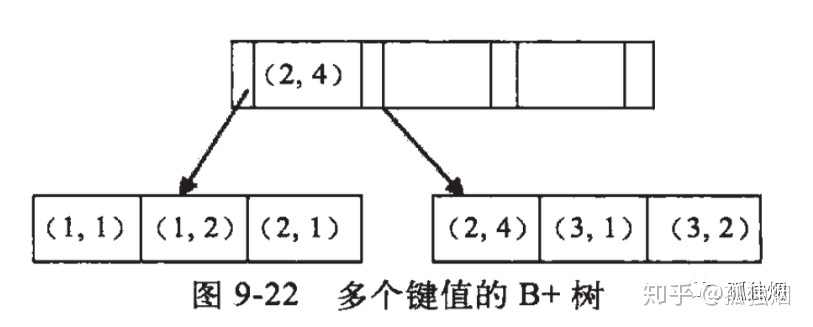
所以看到各叶子节点上数据首先是根据a来排序的,在a相等的情况下才根据b排序;也就是说全局来看a是有序的`1,1,2,2,3,3`,而b是全局乱序的`1,2,1,4,1,2`,所以直接走b是没办法利用索引的,而直接走a是可以利用索引的。
从局部来看当a确定后,b的值也是有序的,例如a=1对应b的值为`1,2`,当a=2时b的值为`1,4`有序,因此`a=4 AND b=5`是可以利用到索引的,而`a>4 AND b=5`就没办法利用索引了,因为当a为一个范围的时候b的值不一定是有序的,无法利用索引。
# Reference
[谈谈MySQL联合索引的理解 - 孤独烟的文章 - 知乎](https://zhuanlan.zhihu.com/p/115778804)

面试官:说说你对MySQL联合索引(复合索引)的理解
