# 索引是什么
索引(Index)是帮助数据库高效查找所需要数据的数据结构。索引是在基于数据库表创建的,它包含一个表中某些列的值以及记录对应的地址,并且把这些值存储在一个数据结构中。最常见的就是使用哈希表、B+树作为索引。
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
# 为什么要使用索引
我们知道,数据库查询是数据库最主要的功能之一。而查询速度当然是越快越好。而当数据量越来越大的时候,查询花费的时间会随之增长。而索引,可以加速数据的查询。因为索引是有序排列的。
举个例子来说,假设我们有一个数据库表Employee,这个表分别有三个字段:name,age,address。假设表中有1000条记录。
假如没有使用索引,当我们查询名为“Jesus”的雇员的时候,即调用:
select name,age,address from Employee where name = 'Jesus';
此时数据库不得不在Employee表中对这1000条记录一条一条的进行判断name字段是否为“Jesus”。这也就是所谓的全表扫描。
而当我们在Employee表上的name字段上创建索引时,当我们查询名为“Jesus”的雇员时,会通过索引查找去查询名为“Jesus”的雇员,因为该索引已经按照字母顺序排列,因此要查找名为“Jesus”的记录时会快很多,因为名字首字母为“J”的雇员都是排列在一起的。通过该索引,能获取到表中对应的记录。
例如以链表结构为例,假设第一个name=“Jesus”的节点是第499个节点,最后一个name=“Jesus”的节点是第500个节点,那么只需要遍历501个节点就可以了。当发现第501个节点的name字段不为“Jesus”,后面的499个节点也就无需遍历了。通过索引,我们就找到了name为“Jesus”的节点,而通过该节点的另一个属性(关键字字段在数据库表的对应的记录的地址),我们就能获取到Employee表中满足条件name=“Jesus”的记录了。
通过使用索引,查询判断的次数就从1000次缩小到了501次了。起到了加速了查询效率。但实际上数据库中索引的结构,并不是链表结构。
# 哪些数据结构可能可以用来做索引?
## Hash(MyISAM InnoDB √)
- [x] 实现简单
- [x] 查询性能高效 为O(1)
- [ ] 容易发生碰撞,退化为O(n)
- [ ] 不支持范围查找
## 有序数组
- [x] 支持范围查找
- [ ] 维护成本大
## AVL
- [ ] 树深度太大(1个节点存一个数据)
- [ ] 磁盘IO次数太多,最坏情况为树的深度
- [ ] 逻辑上相邻的节点在物理结构上可能相差很远,没办法充分利用磁盘的**预读功能**
> 局部性原理与磁盘预读:
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分之一,因此为了提高效率,**要尽量减少磁盘I/O**。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,**即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。**
这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
## B树(MyISAM √)
- [x] IO次数少(节点大小为磁盘页的大小,m叉树m=页大小/数据项大小)
- [ ] 数据存在所有的节点中,深度还有优化空间
- [ ] 范围查找性能不够好 --> 例如极端情况下我们"*范围查找*"全表时至少需要中序遍历全表一次
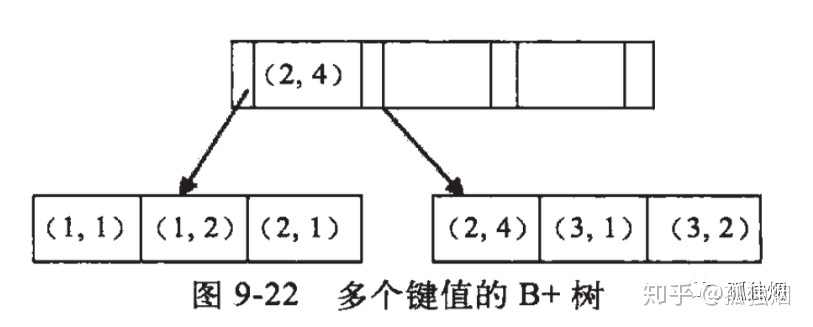
## B+树(InnoDB √)
- [x] IO次数少,平均2~3次查找就可以查找千万级别的数据
- [x] 根节点常驻内存,非叶子节点存索引项,叶子节点存数据本身(树的深度进一步被降低了)
> 这里做一个补充说明:
由于B树的非叶子节点还需要存一些数据,而单个节点的大小是固定的,这就导致了**每个节点内能存放索引的数量减少了,也就是说装满所有索引的所需要的节点数/层数会变多**,(我们说希望减少IO一定程度上表现为希望尽快命中索引)
因此将叶子节点存放数据本身、非叶子节点只存放索引项会进一步使得索引树变得**更加"矮胖"**
- [x] 叶子节点之间用双向链表的结构连接,便于实现范围查找
- [x] B+树 页的概念天然地和磁盘块/页的概念对应,为IO设计
## 跳表[指大容量的DataBase、主要以外存为主]
- [ ] level太高,数据存储不紧凑、空间浪费
- [ ] 查询产生大量跨页的IO
> Redis使用跳表的原因:
> - 与RBT相比实现更加简单,范围查找支持较好
> - 更加灵活 可以调整索引构建策略(调整p值:决定每个结点的平均索引高度,p越小空间复杂度越低,时间复杂度越高) 有效实现时空复杂度之间的平衡[1]
# Reference
[1] [《Skip Lists: A Probabilistic Alternative to Balanced Trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)
聊一聊索引的数据结构