##### 大数定理说明了,足够大的样本能几乎肯定地反映出总体的真实组成的
###### Python zip()函数
<pre class="EnlighterJSRAW" data-enlighter-language="null">>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = [4, 5, 6, 7, 8]
>>> zipped = zip(a, b)
[(1, 4), (2, 5), (3, 6)]
>>> zipped = zip(a, c) #元素个数与最短的列表相一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # zip(*tuple) 解压返回二维矩阵
[(1, 2, 3), (4, 5, 6)]</pre>
##### I. 不同的训练算法 硬/软投票
<pre class="EnlighterJSRAW" data-enlighter-language="null">log_clf = LogisticRegression(solver="liblinear", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma="auto", probability=True, random_state=42) //超参数probability=True
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft') //软投票
voting_clf.fit(X_train, y_train)</pre>
##### II. 算法相同 在不同的训练集随机子集上进行训练
- 采样时样本放回 bagging(bootstrap aggregating 自举汇聚法/自助法)
- 采样时不放回 pasting **通常bagging效果好**
- 聚合函数
- 统计法 = 分类
- 平均法 = 回归
<pre class="EnlighterJSRAW" data-enlighter-language="null">//当每个子分类器支持预测类别概率(即具有predict_proba()方法,默认采用软投票
from sklearn.ensemble import BaggingClassifier //BaggingRegressor 回归
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1, random_state=42) //500个决策树,每个决策树选取100个样本训练 //n_jobs=-1表示使用所有可用内核 bootstrap = False 使用pasting oob_score = True 包外评估
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))</pre>
### 随机森林
<pre class="EnlighterJSRAW" data-enlighter-language="null">from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators = 500, max_leaf_nodes = 16 ,n_jobs = -1)
rnd_clf.fit(x_train, y_train)</pre>
- 每个节点分裂时随机选择特征的决策树组成的森林称为极端随机数,Extra-Trees,训练要快得多。很难说哪个效果更好,应该2种都尝试一遍、分别用**交叉验证、网格搜索法**进行比较。
<pre class="EnlighterJSRAW" data-enlighter-language="null">from sklearn.ensemble import ExtraTreesClassifier
</pre>
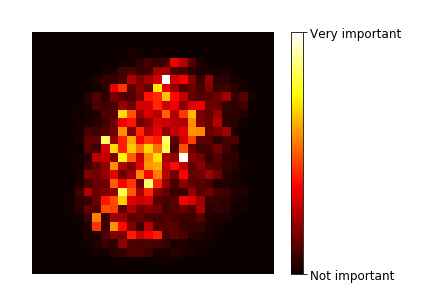
##### 特征重要性
- 重要的特征通常更靠近根节点
- 计算一个特征在所有树上的平均深度可以估算一个特征的重要程度
- Scikit-Learn自动计算,通过featur_importances_访问
- 因而采用随机森林 可以**快速了解什么特征比较重要**
<pre class="EnlighterJSRAW" data-enlighter-language="null">rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
rnd_clf.fit(mnist["data"], mnist["target"])
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.hot,
interpolation="nearest")
plt.axis("off")
plot_digit(rnd_clf.feature_importances_)
cbar = plt.colorbar(ticks=[rnd_clf.feature_importances_.min(), rnd_clf.feature_importances_.max()])
cbar.ax.set_yticklabels(['Not important', 'Very important'])
save_fig("mnist_feature_importance_plot")
plt.show()
</pre>
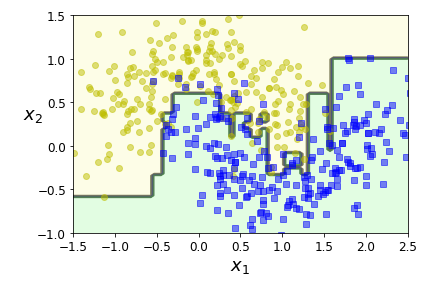
### AdaBoost 自适应提升法,Adaptive Boosting
> 提升法, 将几个弱学习器结合一起成为强学习器的任意集成方法
>
> 大多数提升法的总体思路是循环训练预测器,每一次都对其前序做一些改进
- 每个新的预测器对其前序进行纠正的方法之一就是**更关注前序拟合不足的样本**,这就是**AdaBoost**采用的方法
- 构建n个基础分类器,训练1个 --> 预测 -->对错误分类的样本增加其相对权重 --> 更新权重对第二个分类器训练--> ····· --> end
- 无法并行
<pre class="EnlighterJSRAW" data-enlighter-language="null">from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
algorithm="SAMME.R", learning_rate=0.5, random_state=42)
ada_clf.fit(X_train, y_train)
plot_decision_boundary(ada_clf, X, y)
</pre>
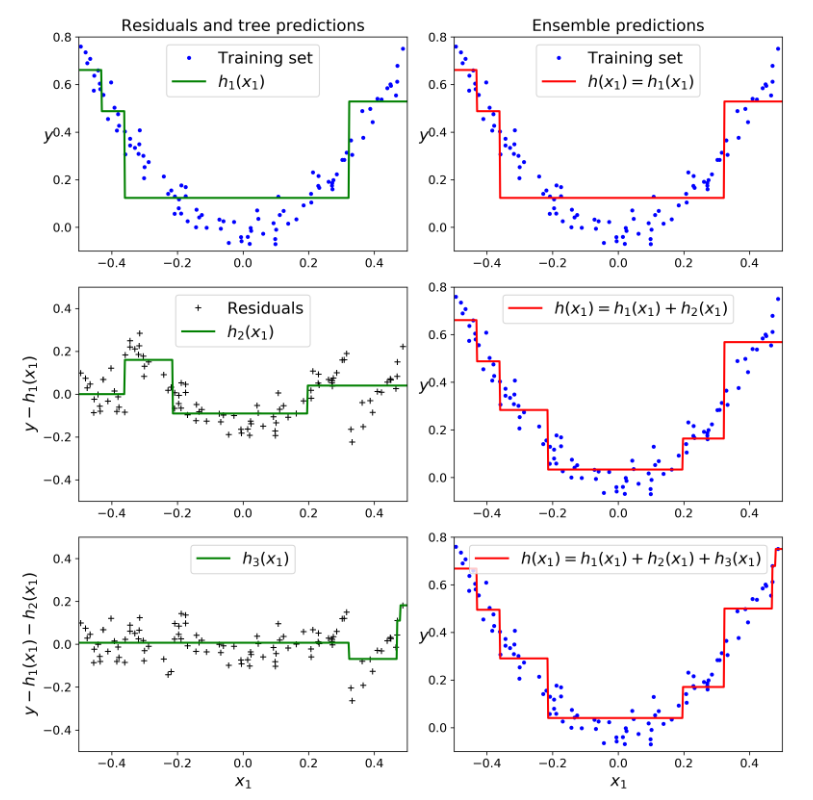
### Gradient Boosting 梯度提升法
<pre class="EnlighterJSRAW" data-enlighter-language="null"># 生成数据
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
# 每一个预测其针对前一个预测器的残差进行拟合
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
y2 = y - tree_reg1.predict(X) # 残差
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg2.fit(X, y2)
y3 = y2 - tree_reg2.predict(X) # 残差
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg3.fit(X, y3)
X_new = np.array([[0.8]]) # X_new = array([[0.8]]) 没什么别的意思
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
# output: y_pred = array([0.75026781])
# 可视化过程
def plot_predictions(regressors, X, y, axes, label=None, style="r-", data_style="b.", data_label=None):
x1 = np.linspace(axes[0], axes[1], 500)
y_pred = sum(regressor.predict(x1.reshape(-1, 1)) for regressor in regressors)
plt.plot(X[:, 0], y, data_style, label=data_label)
plt.plot(x1, y_pred, style, linewidth=2, label=label)
if label or data_label:
plt.legend(loc="upper center", fontsize=16)
plt.axis(axes)
plt.figure(figsize=(11,11))
plt.subplot(321)
plot_predictions([tree_reg1], X, y, axes=[-0.5, 0.5, -0.1, 0.8], label="$h_1(x_1)$", style="g-", data_label="Training set")
plt.ylabel("$y$", fontsize=16, rotation=0)
plt.title("Residuals and tree predictions", fontsize=16)
plt.subplot(322)
plot_predictions([tree_reg1], X, y, axes=[-0.5, 0.5, -0.1, 0.8], label="$h(x_1) = h_1(x_1)$", data_label="Training set")
plt.ylabel("$y$", fontsize=16, rotation=0)
plt.title("Ensemble predictions", fontsize=16)
plt.subplot(323)
plot_predictions([tree_reg2], X, y2, axes=[-0.5, 0.5, -0.5, 0.5], label="$h_2(x_1)$", style="g-", data_style="k+", data_label="Residuals")
plt.ylabel("$y - h_1(x_1)$", fontsize=16)
plt.subplot(324)
plot_predictions([tree_reg1, tree_reg2], X, y, axes=[-0.5, 0.5, -0.1, 0.8], label="$h(x_1) = h_1(x_1) + h_2(x_1)$")
plt.ylabel("$y$", fontsize=16, rotation=0)
plt.subplot(325)
plot_predictions([tree_reg3], X, y3, axes=[-0.5, 0.5, -0.5, 0.5], label="$h_3(x_1)$", style="g-", data_style="k+")
plt.ylabel("$y - h_1(x_1) - h_2(x_1)$", fontsize=16)
plt.xlabel("$x_1$", fontsize=16)
plt.subplot(326)
plot_predictions([tree_reg1, tree_reg2, tree_reg3], X, y, axes=[-0.5, 0.5, -0.1, 0.8], label="$h(x_1) = h_1(x_1) + h_2(x_1) + h_3(x_1)$")
plt.xlabel("$x_1$", fontsize=16)
plt.ylabel("$y$", fontsize=16, rotation=0)
save_fig("gradient_boosting_plot")
plt.show()
</pre>
- 还是用下面的方法写吧。
<pre class="EnlighterJSRAW" data-enlighter-language="null">
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0, random_state=42)
gbrt.fit(X, y)
# learning_rate:缩放每棵树的贡献 调小learning_rate需要更多的树来拟合数据集,泛化效果更好
# 这种方法被称为收缩的正则化方法
gbrt_slow = GradientBoostingRegressor(max_depth=2, n_estimators=200, learning_rate=0.1, random_state=42)
gbrt_slow.fit(X, y)
# 可视化
plt.figure(figsize=(11,4))
# 121 1代表行 2代表列 1代表序号
plt.subplot(121)
plot_predictions([gbrt], X, y, axes=[-0.5, 0.5, -0.1, 0.8], label="Ensemble predictions")
plt.title("learning_rate={}, n_estimators={}".format(gbrt.learning_rate, gbrt.n_estimators), fontsize=14)
plt.subplot(122)
plot_predictions([gbrt_slow], X, y, axes=[-0.5, 0.5, -0.1, 0.8])
plt.title("learning_rate={}, n_estimators={}".format(gbrt_slow.learning_rate, gbrt_slow.n_estimators), fontsize=14)
save_fig("gbrt_learning_rate_plot")
plt.show()
</pre>
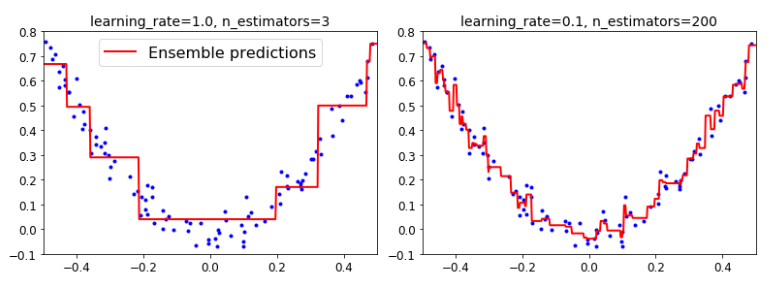
- 左图训练树过少欠拟合, 右图树过多而过拟合
- **寻找最佳数量** --> **早停法** staged_predict()
<pre class="EnlighterJSRAW" data-enlighter-language="null">import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=49)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120, random_state=42)
gbrt.fit(X_train, y_train)
errors = [mean_squared_error(y_val, y_pred)
for y_pred in gbrt.staged_predict(X_val)]
bst_n_estimators = np.argmin(errors) + 1 //argmin返回errors最小的索引值,即树的数目
gbrt_best = GradientBoostingRegressor(max_depth=2,n_estimators=bst_n_estimators, random_state=42)
gbrt_best.fit(X_train, y_train)</pre>

- warm_start = True
- 当连续5次迭代未得到改善时,真·提前停止训练
<pre class="EnlighterJSRAW" data-enlighter-language="null">gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True, random_state=42)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if (val_error < min_val_error):
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
if error_going_up == 5:
break # early stopping</pre>
### XGBoost
<pre class="EnlighterJSRAW" data-enlighter-language="null">try:
import xgboost
except ImportError as ex:
print("Error: the xgboost library is not installed.")
xgboost = None
if xgboost is not None: # not shown in the book
xgb_reg = xgboost.XGBRegressor(random_state=42)
xgb_reg.fit(X_train, y_train)
y_pred = xgb_reg.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
print("Validation MSE:", val_error)
# 早停
if xgboost is not None: # not shown in the book
xgb_reg.fit(X_train, y_train,
eval_set=[(X_val, y_val)], early_stopping_rounds=2)
y_pred = xgb_reg.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
print("Validation MSE:", val_error)
</pre>
[读书笔记]Hands-on ML 集成学习&随机森林
